

Confluent launches the industry’s only serverless, cloud-native Flink service to simplify building high-quality, reusable data streams
Confluent announced the open preview of Apache Flink on Confluent Cloud, a fully managed service for stream processing that makes it easier for companies to filter, join, and enrich data streams with Flink.
“Companies globally are leveraging data streaming with Apache Kafka to power real-time experiences,” said Shaun Clowes, Chief Product Officer at Confluent. “While data streaming connects data across an organization, stream processing tools like Apache Flink make it possible to act on that data in real time and accelerate the development of new use cases. Our managed Kafka and Flink offerings are like the peanut butter and jelly of data streaming. They work better together on a unified platform to connect and enrich data so teams can uncover more insights and deliver impactful experiences that move the needle.”
Flink makes it possible for ride sharing companies to match drivers and riders, for banks to alert users on fraudulent activity, and for social media companies to offer personalized content recommendations. However, like Kafka and other open-source technologies, self-managing Flink is operationally complex, has a steep learning curve, and comes with expensive infrastructure and management costs.
Confluent’s Apache Flink service simplifies stream processing, enabling faster application development
Apache Flink on Confluent Cloud allows teams to create high-quality, reusable data streams that can be delivered anywhere in real time. With Confluent’s fully managed and elastically scalable Flink service, teams can reduce the architectural complexity and operational burdens of stream processing to enrich streaming data and power innovative use cases.
Teams using Apache Flink on Confluent Cloud can:
- Effortlessly filter, join, and enrich data streams with Flink, the standard for stream processing.
- Enable high-performance and efficient stream processing at any scale, without the complexities of infrastructure management.
- Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance.
Apache Flink is available as an open preview for Confluent Cloud customers using AWS in select regions for testing and experimentation purposes. General availability is coming soon.
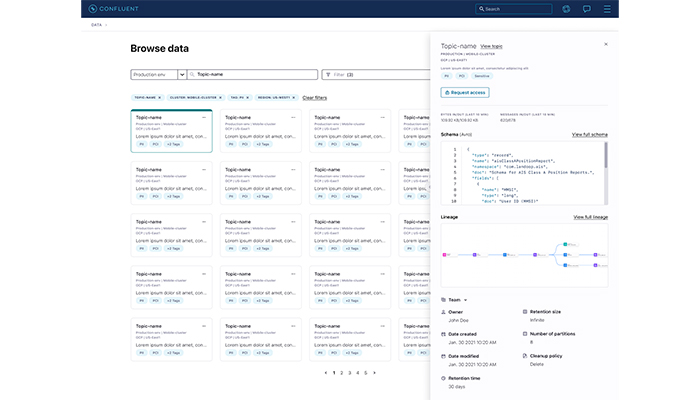
Data Portal
In addition, Confluent announced Data Portal to help teams discover all the real-time data streams within their organizations. This solution enables teams to:
- Search, discover, and explore existing topics, tags, and metadata across the organization with end-to-end visibility to choose the data most relevant for their projects.
- Seamlessly and securely request access to data streams and trigger an approval workflow that connects the user with the data owner, all within the Confluent Cloud UI.
- Easily build and manage data products to power streaming pipelines and applications by understanding, accessing, and enriching existing data streams.
Confluent Cloud customers will be able to experience Data Portal’s features to easily find data streams soon.